HandAvatar:
Free-Pose Hand Animation and Rendering from Monocular Video
CVPR 2023



Demonstration of HandAvatar. (a) Personalized hand rendering. From left to right: hand mesh, compositional occupancy, albedo, illumination, shaded appearance, and ground truth; (b) three groups of texture editing in terms of lighting, albedo, and shadow (by altering the self-occlusion effect of thumb); (c) free-pose hand animation and photo-realistic rendering.
Abstract
We present HandAvatar, a novel representation for hand animation and rendering, which can generate smoothly compositional geometry and self-occlusion-aware texture. Specifically, we first develop a MANO-HD model as a highresolution mesh topology to fit personalized hand shapes. Sequentially, we decompose hand geometry into per-bone rigid parts, and then re-compose paired geometry encodings to derive an across-part consistent occupancy field. As for texture modeling, we propose a self-occlusion-aware shading field (SelF). In SelF, drivable anchors are paved on the MANO-HD surface to record albedo information under a wide variety of hand poses. Moreover, directed soft occupancy is designed to describe the ray-to-surface relation, which is leveraged to generate an illumination field for the disentanglement of pose-independent albedo and pose-dependent illumination. Trained from monocular video data, our HandAvatar can perform free-pose hand animation and rendering while at the same time achieving superior appearance fidelity. We also demonstrate that HandAvatar provides a route for hand appearance editing.
Video
Overview
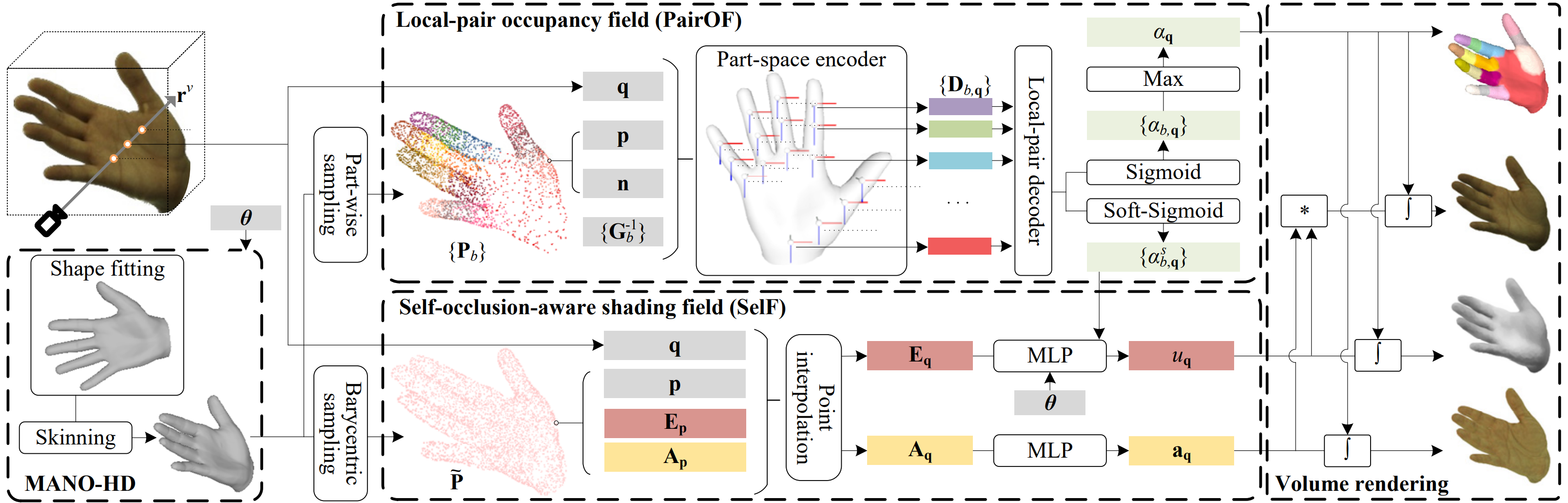
HandAvatar overview. Given hand pose, MANO-HD produces personalized mesh, while PariOF yields accordingly occupancy field. SelF estimates albedo and illumination fields under self-occlusion. Then, hand appearance is synthesized by volume rendering.
Disentanglement of Albedo and Illumination
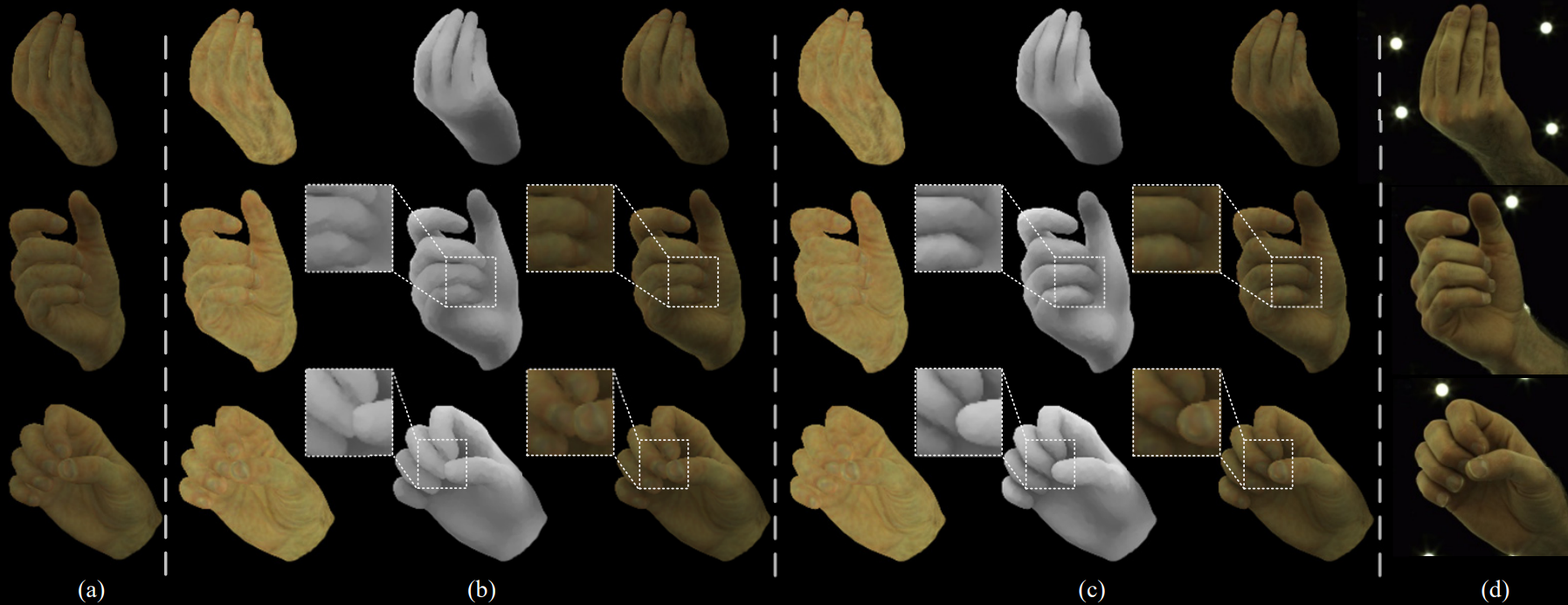
Effects of the disentangled albedo and illumination fields in SelF. (a) Coupled albedo and illumination. (b,c) Disentangled albedo and illumination; directed soft occupancy is not involved in (b); from left to right: albedo, illumination, shaded image. (d) Ground truth.
Comparisons with Prior Arts
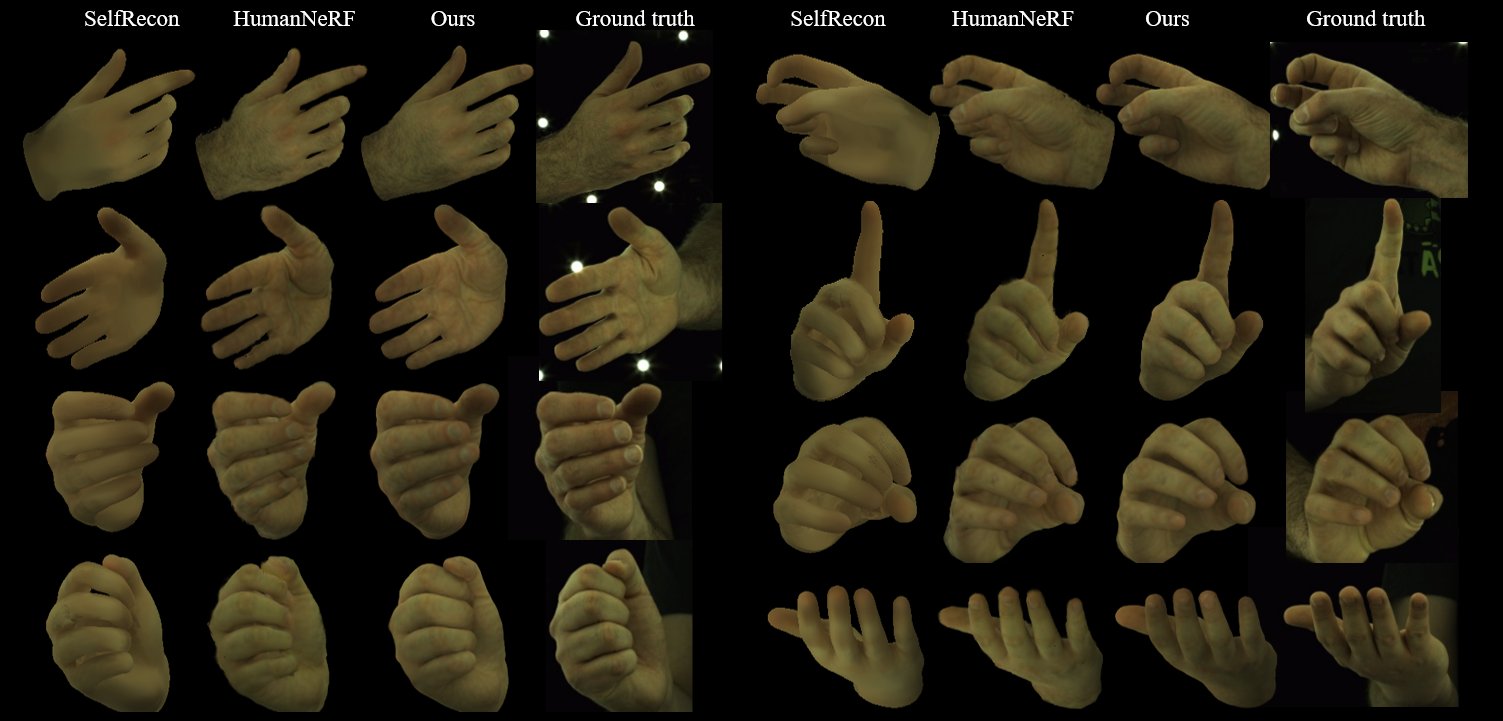
Visualization results of SelfRecon, HumanNeRF, and our HandAvatar on free-pose animation and rendering.
Dynamic Results
We compare HandAvatar with prior arts.
We show the effects of our proposed directed soft occupancy.
Citation
@inproceedings{bib:handavatar,
title={Hand Avatar: Free-Pose Hand Animation and Rendering from Monocular Video},
author={Chen, Xingyu and Wang, Baoyuan and Shum, Heung-Yeung},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2023}
}
Acknowledgements
We thank Yu Deng for the fruitful advice and discussion to improve the paper.
The website template was adapted from GRAM.